
ใน ep ก่อน ๆ เราสอนเรื่อง Image Classification คือ 1 รูป 1 หมวด แล้วต่อมาเป็น Multi-label Image Classification คือ 1 รูป หลายหมวด
มาถึงใน ep นี้ เราจะมาสอนเรื่อง Image Segmentation แยกส่วนภาพ คือ 1 Pixel 1 หมวด หมายถึง ใน 1 รูป เราจะจำแนก Pixel หลายล้าน Pixel ทีละจุด ว่าแต่ละจุด คืออะไร
Image Segmentation คืออะไร
Image Segmentation หรือ Semantic Segmentation คือ จำแนกว่า Pixel หลายล้าน Pixel แต่ละจุด คืออะไร จะได้ผลออกมาเป็นแบ่งเป็นพื้นที่สีต่าง ๆ ซึ่งแต่ละสีหมายความถึงลักษณะที่แตกต่างกัน เช่น บ้าน, ถนน, ต้นไม้, etc.
เปรียบเทียบกับ Image Classification คือ การจำแนกรูปทั้งรูป และ Instance Segmetation คือ เหมือน Semantic Segmentaion แต่เพิ่มเติมคือสามารถบอกแยกแต่ละ Instance ของ Object ได้ เช่น แยกต้นไม้แต่ละต้นได้ด้วย ไม่ใช่ถมเป็นสีเดียวกันหมดว่าเป็นต้นไม้
จากที่สมัยก่อนที่จะมี Deep Learning การ Segmentation เราต้องทำ Feature Engineering แบ่งภาพตามเฉดสี, ตาม Contrast, ตามขอบ เราสามารถใช้ Deep Neural Networks มาเทรน End-to-End ได้เลย
การแยกส่วนภาพ จำแนกที่ละเอียดขึ้น ชี้ชัดลงไปถึงว่า พื้นที่ส่วนไหนของรูป เป็นอะไร แบบนี้ทำให้เรานำมาใช้ประโยชน์ได้ใน Application ที่หลากหลายมากขึ้น เช่น
ตัวอย่าง
วิเคราะห์ รูปถ่าย X-Ray, MRI
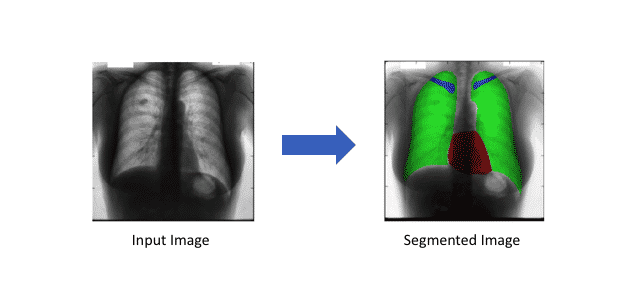
วิเคราะห์ รูปถ่ายผิวหนัง

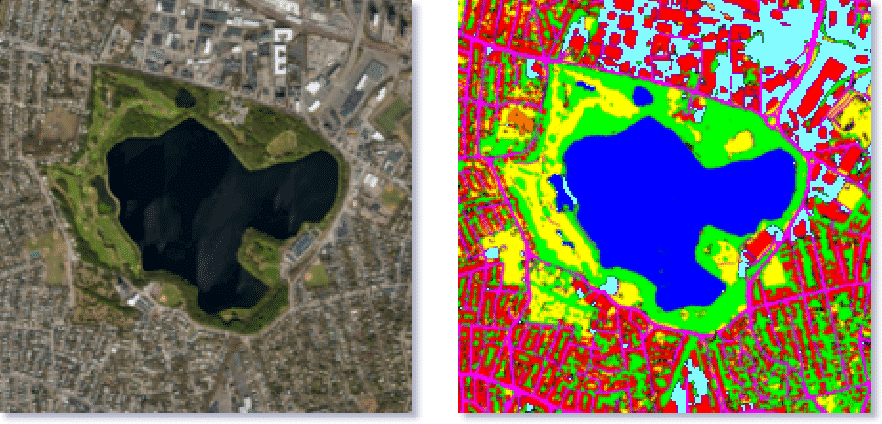
วิเคราะห์ รูปถ่ายดาวเทียม รูปถ่ายทางอากาศ
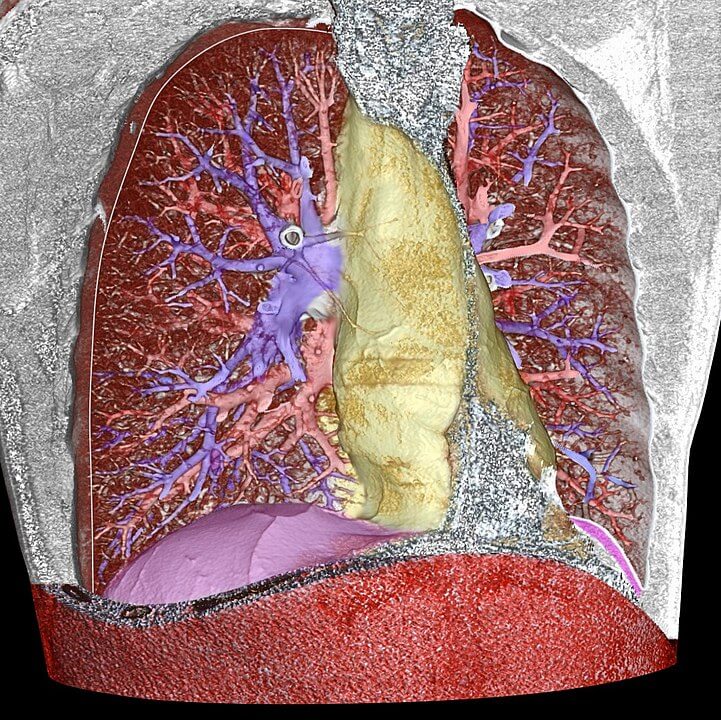
Volume Segmentation วิเคราะห์รูปถ่าย CT scan แบบ 3D
- สีน้ำเงิน คือ pulmonary arteries
- สีแดง คือ pulmonary veins (and also the abdominal wall)
- สีเหลือง คือ the mediastinum
- สีม่วง คือ the diaphragm
Dataset ชุดข้อมูลที่เราใช้
Dataset ที่เราจะใช้แยกส่วนภาพ ในครั้งนี้ ประกอบด้วยรูปถ่าย ขณะขับรถไปตามท้องถนนทั่วไป ขนาด 960×720 Pixel จำนวน 101 รูป โดยที่แต่ละ Pixel ได้ถูกกำหนดสีด้วยมือให้เป็น อยู่ใน 1 ใน 32 หมวดหมู่ เช่น ตึก-สีแดง, พื้นถนน-สีม่วง, คนขี่จักรยาน-สีฟ้า, …, etc. ดังด่านล่าง



U-Net Architecture
เคสนี้เราจะเปลี่ยนมาใช้ U-Net แทน Convolution Neural Network (CNN) ปกติ เนื่องจาก โดย Design แล้ว CNN แต่ละ Layer จะลดมิติกว้าง x ยาว ไปเพิ่มมิติจำนวน Kernel ทำให้ขนาด Output กว้าง x ยาวจะเล็กลงเรื่อย ๆ แต่ในเคสนี้ เราต้องการ Output ที่มีขนาดกว้างยาวเท่ากับ Input
Architecture ของ CNN ทำให้ขนาดกว้าง x ยาว ลดลงเรื่อย ๆ เรื่องสถาปัจยกรรม Convolution Neural Network เราจะอธิบายต่อไป
แต่ Architecture ของ U-Net จะมี CNN 2 ขา โดย ขา Encode จะย่อ ขอ Decode จะขยาย ทำให้สุดท้ายขยายขนาดให้กลับมาเท่าเดิม
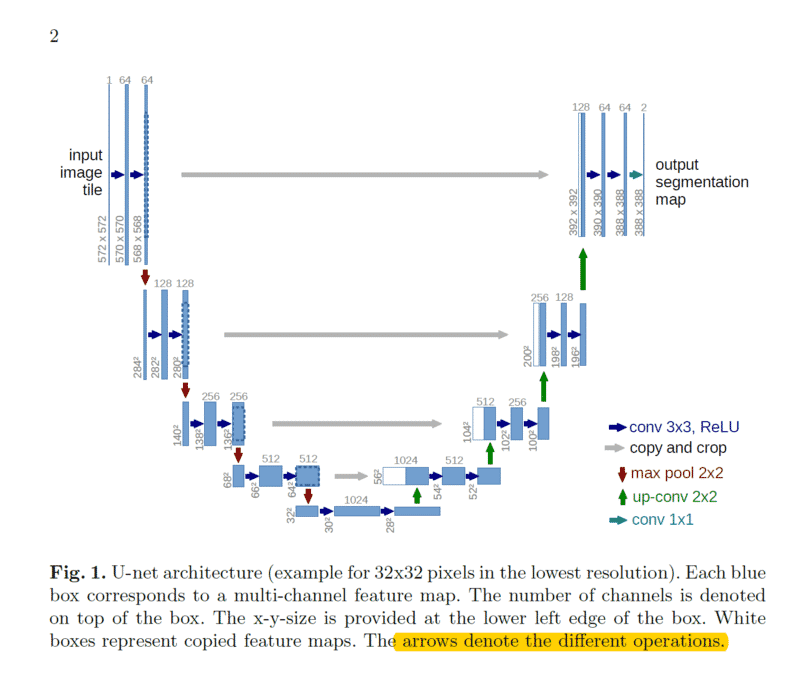
เรามาเริ่มกันเลย
Credit
- Julien Fauqueur, Gabriel Brostow, Roberto Cipolla, Assisted Video Object Labeling By Joint Tracking of Regions and Keypoints, IEEE International Conference on Computer Vision (ICCV’2007) Interactive Computer Vision Workshop. Rio de Janeiro, Brazil, October 2007
- http://mi.eng.cam.ac.uk/research/projects/VideoRec/CamVid/
- https://towardsdatascience.com/understanding-semantic-segmentation-with-unet-6be4f42d4b47
- https://www.semanticscholar.org/paper/A-color-space-study-for-skin-lesion-segmentation-Nisar-Ch’ng/010efc0e25054b866534b666c5b1652d68063ca0/figure/1
- https://www.semanticscholar.org/paper/Deep-Fusion-of-Imaging-Modalities-for-Semantic-of-Sundelius/59cbe15b43e6ca172fce40786be68340f50be541/figure/0
- https://en.wikipedia.org/wiki/Image_segmentation#/media/File:3D_CT_of_thorax.jpg
- https://pytorch.org/tutorials/beginner/blitz/neural_networks_tutorial.html
- https://arxiv.org/abs/1505.04597


{kind=link}