
ในการเทรนโมเดล Deep Learning ที่มีจำนวนหลาย ๆ Layer จำเป็นต้องใช้ GPU เร็ว ๆ แต่เราไม่ควรพิจารณาแค่ความเร็ว ความใหม่ของ GPU เพียงอย่างเดียว ขนาด Memory ของ GPU ก็มีความสำคัญอย่างมาก GPU ควรมี Memory ขนาดใหญ่เพียงพอกับขนาดโมเดล และขนาดของข้อมูล
เพื่อที่จะลดเวลาในการเทรน ที่จะต้องเสียเวลา ก็อปปี้ข้อมูลเข้าออก ระหว่าง Disk, CPU Memory และ GPU Memory ทำให้ CUDA Core ของ GPU ที่มีความเร็วสูง กลับว่างงาน เพราะต้องรอข้อมูล
nvidia-smi
nvidia-smi ย่อมาจาก Nvidia System Management Interface เราสามารถเช็คว่าตอนนี้ GPU ทำงานประสิทธิภาพเป็นอย่างไร ด้วยคำสั่ง
watch -n 1 nvidia-smi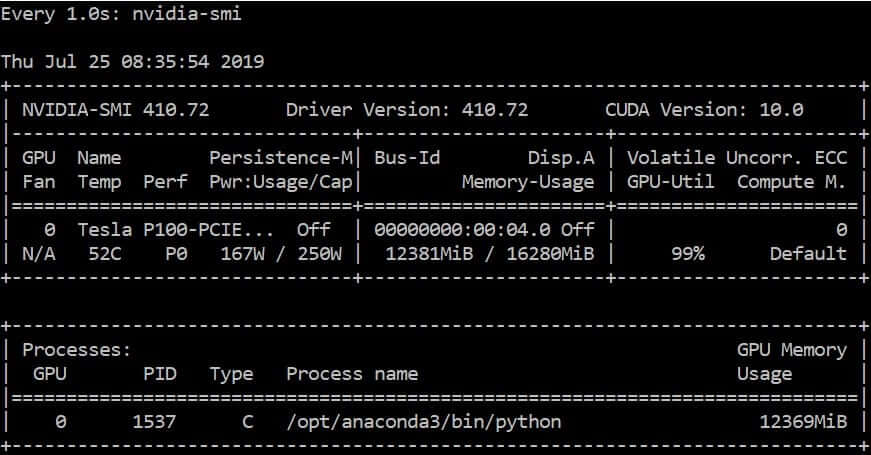
คำสั่ง watch -n 1 ใช้ในการเรียกดูคำสั่งซ้ำ ๆ ทุก 1 วินาที คำสั่งที่เรียก คือ nvidia-smi ที่มากับ driver ของ GPU ยี่ห้อ Nvidia จะแสดงค่าต่าง ๆ เช่น
- Memory Usage: 12381Mib / 16280Mib คือ หน่วยความจำที่ใช้อยู่ / หน่อยความจำทั้งหมด
- GPU-Util: 99% คือ ตอนนี้ GPU กำลังทำงานเต็มที่ 99%
- Pwr: Usage/Cap 167W / 250W คือ กำลังไฟฟ้าที่ใช้ / กำลังไฟสูงสุด
- Temp: 52C อุณหภูมิ 52 องศาเซลเซียส
- Name: Tesla P100-PCIE คือ ชื่อรุ่นของ GPU
- Driver Version: 410.72 คือ เวอร์ชันของไดร์เวอร์ ควรใหม่สุดเท่าที่ GPU จะรับได้
- Process name: /opt/anaconda3/bin/python คือ โปรเซสที่ใช้งาน GPU อยู่ ณ ตอนนี้
ทำให้เราสามารถปรับจูน Hyper Parameter ของโมเดล เช่น Batch Size, Dropout, Models เพื่อให้ใช้งาน GPU อย่างเต็มประสิทธิภาพ ไปจนกระจายงานไปให้หลาย ๆ GPU ช่วยกัน (กรณีมีหลาย GPU) หรือส่งไปเทรนบน Cloud เป็นต้น
คำสั่งอื่นๆ ที่น่าสนใจ
nvidia-smi -l 1nvidia-smi -Lnvidia-smi dmonnvidia-smi pmonnvidia-smi -i 0 -qnvidia-smi --query-gpu=timestamp,pstate,temperature.gpu,utilization.gpu,utilization.memory,memory.total,memory.free,memory.used --format=csv -l 1nvtopgpustats
nvtop และ gpustats ต้องติดตั้งเพิ่มเติม

