นอกเหนือจากข้อมูลตัวเลข Cardinal ค่าต่อเนื่อง (Continuous) เราจะพบ Feature ที่เป็นข้อมูลค่าไม่ต่อเนื่อง (Discrete) ในรูปแบบตัวเลขแบบ Ordinal, Nominal หรือข้อความ คือ มีค่าที่เป็นไปได้จำกัด ระบุว่าอยู่หมวดหมู่ไหน เช่น วันในสัปดาห์ 1 จันทร์, 2 อังคาร, 3 พุธ, … คือ 1 ใน 7 ค่าเท่านั้น
เราจะไม่สามารถทำ Rescale, Normalize แบบใน ep 2 ได้ แล้วเราจะเตรียมข้อมูลชนิดนี้อย่างไรดี ถึงจะป้อนให้ Machine Learning ใช้เทรนได้

Nominal Number ข้อมูลไม่มีลำดับ
Nominal Number ความหมายของข้อมูลไม่มีลำดับเช่น 45 สีแดง, 85 สีเขียว, 52 สีน้ำเงิน, 23 สีเหลือง
เราสามารถใช้ One-Hot Encoding แปลงค่าแต่ละค่า เป็น 1 Dummy Feature ได้

Ordinal Number ข้อมูลมีลำดับ
Ordinal Number ข้อมูลมีลำดับ อยู่ในความหมายของข้อมูล เช่น 100 ปริญญาตรี < 200 ปริญญาโท < 300 ปริญญาเอก
เราจะใช้การ Map 100 ปริญญาตรี = 0, 200 ปริญญาโท = 1, 300 ปริญญาเอก = 2
Embedding
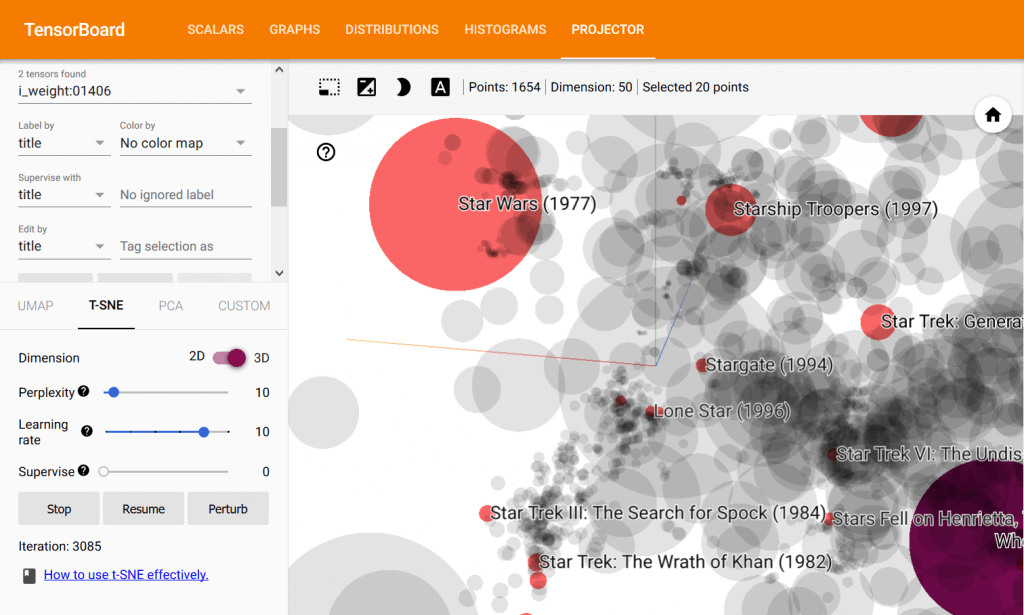
เราสามารถนำ Embedding มาใช้กับข้อมูล Category ได้ ทำให้โมเดล Machine Learning จับ Pattern ความหมายที่แฝงอยู่ในแต่ละ Category ได้ดีมากขึ้น ตัวอย่าง เช่น วันจันทร์ อังคาร พุธ พฤหัส ศุกร์ แทนที่จะมองเป็นมิติเดียว อาจะแตกต่างกันพอ ๆ กัน แต่เราสามารถมองเป็นหลายมิติ วันเสาร์ อาทิตย์ อาจใกล้เคียงกันมากกว่า และจับกลุ่มอยู่ห่างคนละ Latent Space กับกลุ่ม 5 วันแรก การใช้ Map เป็นมิติเดียว เป็นเลขเรียงกัน 0-6 หรือ One-Hot Encoding 6 Dummy Feature อาจทำให้สูญเสียความหมายนี้ไป
ใน ep ก่อน ๆ เราได้สอนเรื่อง Embedding ของ User และ Item ใน Collaborative Filtering และการนำ Embedding มาทำ Visualization เพื่อตีความ ให้เข้าใจข้อมูลได้มากขึ้น
เรามาเริ่มกันเลยดีกว่า
![]()
![]()

